Nvidia, Large Language Models (LLMs) and Artificial Intelligence (AI).
A quick review

In the last few days, there has been a lot of market excitement following the Nvidia Results regarding Large Language Models (LLMs) and Artificial Intelligence (AI).
Nvidia Results
On 24th May 2023, Nvidia reported quarterly results and the company’s numbers comfortably beat expectations on revenues and profits for the quarter ending March 2023. However, what made the market collectively gasp, was the forecast for the next quarter to end June 2023. Nvidia guided the next quarter revenue to US$ 11bn compared with analysts’ expectations of about US$ 7.2bn, or 52% quarter-over-quarter growth. This is some 64% over the quarter ending June 2022 (see below). In addition, they guided to record (Non-GAAP) gross margins of 70% (which will be the highest ever) compared with expectations of 66.6%.
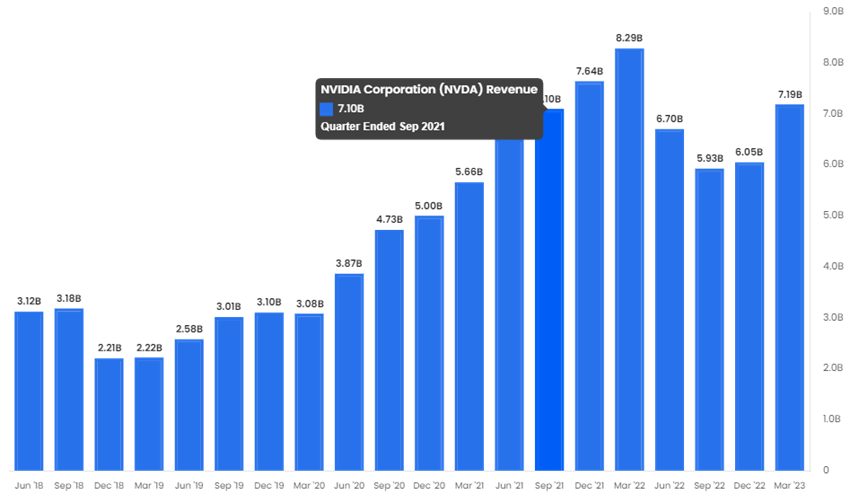

The stock rose by nearly 25% after the results and is now up 187% year to date. Today it briefly hit a market capitalisation of US$ 1 trillion dollars. The reason for the much greater than expected sales forecast is strong demand for Nvidia Graphics Processing Units (GPUs) driven by developments in Large Language Models (LLMs) and AI.
Investors must get up to speed in trying to understand this subject quickly. Fortunately, there is an article written today by Doug O'Laughlin from Fabricated Knowledge called “The Coming Wave of AI, and How Nvidia Dominates” interested reader can find the full article here but I will summarise it below:
Doug O'Laughlin notes that LLMS are sweeping the world right now. CHTP GPT from Open.ai and Google’s Bard have alerted the world to the potential of AI. They are trained on a large body of data to learn the relationships in language, which can then be used to answer general questions. Each LLM model has a few key attributes:
· the model's size (parameters),
· the size of the training data (tokens),
· the cost to compute the training,
· and the performance after training (inference)
Research has shown the larger the models are, the better they will perform. These very large models must have somewhere they can be stored (memory) and something which must train the models (compute) and both these factors mean likely strong demand for semiconductors.
Training and Inference
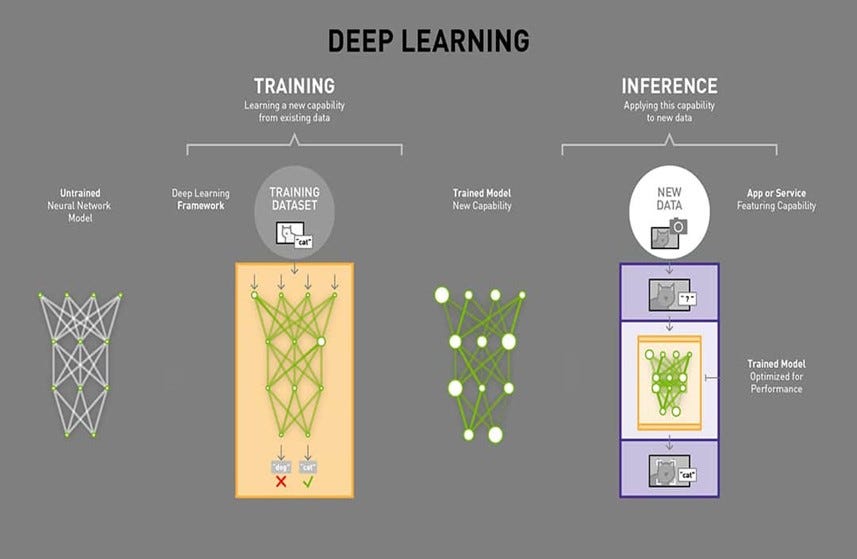
Source: Doug O'Laughlin: Fabricated Knowledge
AI requires Training followed by Inference.
“Training” refers to teaching a model to understand the relationship between the input and the output data.
The huge dataset is loaded in batches and the model is asked questions. The model’s answers or predictions are then compared versus the target. The model’s parameters are adjusted, and the process is repeated. The model is trained many times until its parameters and performance are optimized, and it has “learned” all it can from the data. It answers get “better and better” after each iteration.
Each time the dataset is loaded into Graphic Process Units (GPU) and then taken out takes a lot of bandwidth and computing power.
GPT-4 is 100 trillion parameters which are 400 Terabytes of data. Petabytes of data is moving in and out of the model, calculating differences repeatedly. Doug O'Laughlin notes that training these extremely large models can take 10s if not 100s of millions of dollars.
N.B. 1 terabyte of TB of storage is roughly the same as 16 (64 GB) iPhones or Samsung Galaxy devices- so 400 TB of data = 6400 phones. 1 Petabyte is 1000 terabytes.
Once a model is trained, the next stage is inference.
In Inference, a trained model can accept new input data and then try to predict an output or answer using what it’s learned from training. It doesn’t know the right answer, just the answer that its parameters tell is likely to be correct.
Inference is much simpler than training but is still compute-intensive. The model parameters are loaded into memory, given input data, and then the model predicts the output but does not update its parameters. It just gives out the result.
Training LLMS requires a lot of raw computing power and the semiconductors underlying LLMs are a huge constraint for model performance. Nvidia’s products are essential for most of the training and a meaningful percentage of inference workloads.
From its early days, Nvidia focused in developing Graphic Processing Units (GPUs) which were much in demand in computers, particularly by gamers and later by crypto miners. In the last five years, High Performance Computing (HPC) and Datacentres have driven much of the demand. In contrast, Intel and AMD concentrated much more on Central Processing Units (CPUs) and Intel’s Xeon CPUs have been particularly strong in HPC and Datacentres.
Every query we ask ChatGPT costs as much to run as a CPU in a datacentre for an hour but of course the answer to the query will be consumed in seconds. In other words, the amount of computing it would take to host a website for an hour is being used in a single query. Typically, users of ChatGPT model or Google’s Bard.AI ask multiple queries.
In the future, AI will be embedded into many more aspects of our lives, each person’s usage will run up a bill that will be many times more expensive higher than most websites or SaaS applications that are the typical workloads currently hosted by the hyperscalers such as Amazon AWS, Microsoft Azure, Google GVP etc. “As the world becomes more AI-intensive, hardware demands will soar.”
These models are larger than any one computer, and that’s where stringing multiple computers together into a larger system becomes important. However, doing this gives rise to the interconnect problem.
The ideal perfect computer would have the logic, the memory (data) all in sync and perfectly available to memory. In the real world, the logic is much faster than the memory availability to compute it. Some techniques are used, such as caching and parallel processing to improve the availability of memory to compute. In AI though this simply does not work, as the amount of data being processed is so great.
Each training step must be split into smaller units and parallelized across other computers. The author says “This would be like cutting the larger problem into larger slices like a pizza, and having each slice cooked separately then put back together into a larger pizza. There isn’t an oven big enough to cook 1 whole pizza. The Pizza isn’t finished until each slice is, so how fast all the parts work together is a huge constraint and limit on the entire system. This is the interconnect problem.”
Nvidia has a dominant market share in the best performing GPUs. Its GPUs are connected in a single rack and each of the racks is connected to the other with NVLink, an Nvidia developed networking protocol. The Net effect is each GPU connected in the rack and the racks connected at a very fast speed.
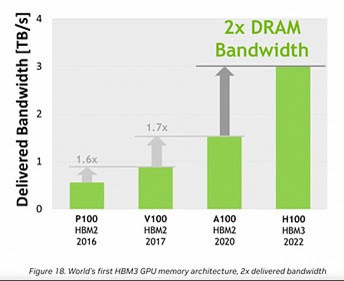
The Chart above shows the capabilities of the various Nvidia GPUs
P100. Pascal 100 was introduced in 2016.
V-100 The NVIDIA® Volta- 100 Tensor Core GPU was introduced in 2017. it offered the performance of nearly 32 CPUs—and was described as enabling researchers to tackle challenges that were once unsolvable.
A-100 – The Ampere 100 introduced in 20202 Powered by the NVIDIA Ampere Architecture, A100 is the engine of the NVIDIA datacentre platform. A100 provides up to 20X higher performance over the prior generation and can be partitioned into seven GPU instances to dynamically adjust to shifting demands. The A100 80GB debuts the world’s fastest memory bandwidth at over 2 terabytes per second (TB/s) to run the largest models and datasets.
H-100 - Hopper 100 - the 9th Generation of Nvidia Datacentre GPUs which was launched in 2022 and is the leading edge for GPUs. It was in production when the Chat-GPT4 was introduced to the world two months ago.
With the NVIDIA NVLink® Switch System, up to 256 H-100 GPUs can be connected to accelerate workloads. Nvidia claim “The H-100’s combined technology innovations can speed up large language models (LLMs) by an incredible 30X over the previous generation to deliver industry-leading conversational AI H-100 is further extending NVIDIA’s market-leading AI leadership with up to 4X faster training and an incredible 30X inference speedup on large language model.”
Nvidia’s DGX is described the gold standard for training By Doug O'Laughlin below:

Each server rack has 8 Nvidia H100 GPUs connected to every other GPU, with 4 NVSwitches connecting the GPUs and 2 Intel Xeon CPUs.
Each rack costs upwards of US$ 500,000 and can train meaningfully large models. Extremely large models take multiple racks to train a single model. For example, GPT-4 was trained on over 16,000 ampere-100 GPUs according to Dylan Patel at Semianalysis.
Imagine a Datacentre with many hundreds of servers in racks in a giant air-conditioned datacentre operated by Amazon AWS or Microsoft Azure. When a model is being trained, each server is working on a small part of the problem in parallel. Jensen Huang’s often talks about how the entire Datacentre is one giant computer in AI Training.
In Doug O'Laughlin’s view, Nvidia is the clear leader in each of the three big market segments they serve. He has a useful diagram which is reproduced below.

At the top of the stack, are the large Cloud hyperscalers who are the large providers of IaaS (Infrastructure as a Service) or the Cloud. In the last decade, organisations and companies have seen the benefit of renting IT infrastructure on the Cloud rather than buying and maintaining in-house in their premises. Most large companies and organisations have migrated their website hosting, data, and workloads etc to the Cloud. The major Cloud providers such as Amazon, Microsoft, Google, Oracle, IBM, and Alibaba have grown strongly on the back of this demand in recent years.
The Cloud providers have invested many hundreds of billions of dollars in vast datacentres in the last five years and this has benefited a range of suppliers including Dell, HP, Intel and Nvidia among others. Now their customers will want to conduct AI-related workloads in the Cloud. The large Cloud providers will have to upgrade their infrastructure and a lot of that will involve buying Nvidia GPUs, Software and Networking products. Jensen Huang has argued the US$ 1 trillion worth of Datacentre investment of recent years is currently 100% CPU but will switch over time to GPU and other smart networking over a few years.
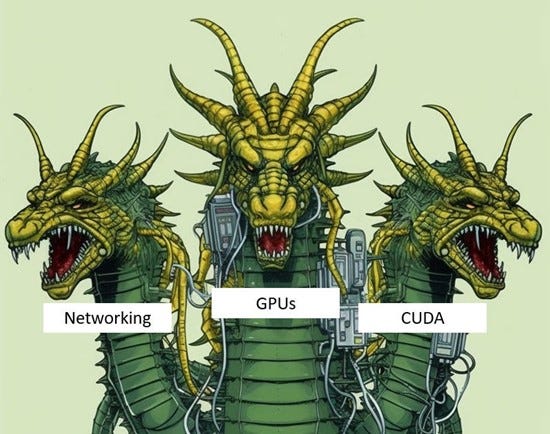
The Author argues that Nvidia has taken meaningful parts of the AI value chain that many larger players cannot replicate meaningfully or quickly. “To beat Nvidia is like attacking a many-headed hydra. You must cut off all three heads at once to have a chance, and meanwhile, each of the heads is already the leader of their respective fields and is working hard to improve and widen its moats. They have moats in networking and systems, Accelerator hardware, and Software all at once.”
CUDA is a parallel computing platform and programming model developed by NVIDIA for general computing on graphical processing units (GPUs). With CUDA, developers can dramatically speed up computing applications by harnessing the power of GPUs. The resulting process is known as accelerated computing. Accelerated computing is required for most AI uses ad is driven Nvidia developed GPUs and CUDA.
“ When asked about one viral (and factually incorrect) chart that purportedly compares the number of parameters in GPT-3 (175 billion) to GPT-4 (100 trillion), Altman called it “complete bullshit.” “The GPT-4 rumor mill is a ridiculous thing.” https://www.theverge.com/23560328/openai-gpt-4-rumor-release-date-sam-altman-interview#:~:text=When%20asked%20about%20one%20viral,mill%20is%20a%20ridiculous%20thing.